注意:这篇文章上次更新于1550天前,文章内容可能已经过时。
最近在看这个,由于原项目网页域名不太好记,就转载重新记录一下。
这里主要记录一些基础内容。
const
const含义
常类型是指使用类型修饰符const说明的类型,常类型的变量或对象的值是不能被更新的。
const作用
- 可以定义常量
const int a=100;-
类型检查
- const常量与
#define宏定义常量的区别:
~~const常量具有类型,编译器可以进行安全检查;#define宏定义没有数据类型,只是简单的字符串替换,不能进行安全检查。~~感谢两位大佬指出这里问题,见:issue
- const定义的变量只有类型为整数或枚举,且以常量表达式初始化时才能作为常量表达式。
- 其他情况下它只是一个
const限定的变量,不要将与常量混淆。
- const常量与
-
防止修改,起保护作用,增加程序健壮性
void f(const int i){
i++; //error!
}-
可以节省空间,避免不必要的内存分配
- const定义常量从汇编的角度来看,只是给出了对应的内存地址,而不是像
#define一样给出的是立即数。 - const定义的常量在程序运行过程中只有一份拷贝,而
#define定义的常量在内存中有若干个拷贝。
- const定义常量从汇编的角度来看,只是给出了对应的内存地址,而不是像
const对象默认为文件局部变量
注意:非const变量默认为extern。要使const变量能够在其他文件中访问,必须在文件中显式地指定它为extern。
未被const修饰的变量在不同文件的访问
// file1.cpp
int ext
// file2.cpp
#include<iostream>
extern int ext;
int main(){
std::cout<<(ext+10)<<std::endl;
}const常量在不同文件的访问
//extern_file1.cpp
extern const int ext=12;
//extern_file2.cpp
#include<iostream>
extern const int ext;
int main(){
std::cout<<ext<<std::endl;
}小结:
可以发现未被const修饰的变量不需要extern显式声明!而const常量需要显式声明extern,并且需要做初始化!因为常量在定义后就不能被修改,所以定义时必须初始化。
定义常量
const int b = 10;
b = 0; // error: assignment of read-only variable ‘b’
const string s = "helloworld";
const int i,j=0 // error: uninitialized const ‘i’上述有两个错误:
- b 为常量,不可更改!
- i 为常量,必须进行初始化!(因为常量在定义后就不能被修改,所以定义时必须初始化。)
指针与const
与指针相关的const有四种:
const char * a; //指向const对象的指针或者说指向常量的指针。
char const * a; //同上
char * const a; //指向类型对象的const指针。或者说常指针、const指针。
const char * const a; //指向const对象的const指针。小结:
如果const位于*的左侧,则const就是用来修饰指针所指向的变量,即指针指向为常量;
如果const位于*的右侧,const就是修饰指针本身,即指针本身是常量。
具体使用如下:
(1) 指向常量的指针
const int *ptr;
*ptr = 10; //errorptr是一个指向int类型const对象的指针,const定义的是int类型,也就是ptr所指向的对象类型,而不是ptr本身,所以ptr可以不用赋初始值。但是不能通过ptr去修改所指对象的值。
除此之外,也不能使用void*指针保存const对象的地址,必须使用const void*类型的指针保存const对象的地址。
const int p = 10;
const void * vp = &p;
void *vp = &p; //error另外一个重点是:允许把非const对象的地址赋给指向const对象的指针。
将非const对象的地址赋给const对象的指针:
const int *ptr;
int val = 3;
ptr = &val; //ok我们不能通过ptr指针来修改val的值,即使它指向的是非const对象!
我们不能使用指向const对象的指针修改基础对象,然而如果该指针指向了非const对象,可用其他方式修改其所指的对象。可以修改const指针所指向的值的,但是不能通过const对象指针来进行而已!如下修改:
int *ptr1 = &val;
*ptr1=4;
cout<<*ptr<<endl;小结:
1.对于指向常量的指针,不能通过指针来修改对象的值。
2.不能使用void*指针保存const对象的地址,必须使用const void*类型的指针保存const对象的地址。
3.允许把非const对象的地址赋值给const对象的指针,如果要修改指针所指向的对象值,必须通过其他方式修改,不能直接通过当前指针直接修改。
(2) 常指针
const指针必须进行初始化,且const指针的值不能修改。
#include<iostream>
using namespace std;
int main(){
int num=0;
int * const ptr=# //const指针必须初始化!且const指针的值不能修改
int * t = #
*t = 1;
cout<<*ptr<<endl;
}上述修改ptr指针所指向的值,可以通过非const指针来修改。
最后,当把一个const常量的地址赋值给ptr时候,由于ptr指向的是一个变量,而不是const常量,所以会报错,出现:const int* -> int *错误!
#include<iostream>
using namespace std;
int main(){
const int num=0;
int * const ptr=# //error! const int* -> int*
cout<<*ptr<<endl;
}上述若改为 const int *ptr或者改为const int *const ptr,都可以正常!
(3)指向常量的常指针
理解完前两种情况,下面这个情况就比较好理解了:
const int p = 3;
const int * const ptr = &p; ptr是一个const指针,然后指向了一个int 类型的const对象。
函数中使用const
const修饰函数返回值
这个跟const修饰普通变量以及指针的含义基本相同:
(1)const int
const int func1();这个本身无意义,因为参数返回本身就是赋值给其他的变量!
(2)const int*
const int* func2();指针指向的内容不变。
(3)int *const
int *const func2();指针本身不可变。
const修饰函数参数
(1)传递过来的参数及指针本身在函数内不可变,无意义!
void func(const int var); // 传递过来的参数不可变
void func(int *const var); // 指针本身不可变表明参数在函数体内不能被修改,但此处没有任何意义,var本身就是形参,在函数内不会改变。包括传入的形参是指针也是一样。
输入参数采用“值传递”,由于函数将自动产生临时变量用于复制该参数,该输入参数本来就无需保护,所以不要加const 修饰。
(2)参数指针所指内容为常量不可变
void StringCopy(char *dst, const char *src);其中src 是输入参数,dst 是输出参数。给src加上const修饰后,如果函数体内的语句试图改动src的内容,编译器将指出错误。这就是加了const的作用之一。
(3)参数为引用,为了增加效率同时防止修改。
void func(const A &a)对于非内部数据类型的参数而言,象void func(A a) 这样声明的函数注定效率比较低。因为函数体内将产生A 类型的临时对象用于复制参数a,而临时对象的构造、复制、析构过程都将消耗时间。
为了提高效率,可以将函数声明改为void func(A &a),因为“引用传递”仅借用一下参数的别名而已,不需要产生临
时对象。
但是函数void func(A &a) 存在一个缺点:
“引用传递”有可能改变参数a,这是我们不期望的。解决这个问题很容易,加const修饰即可,因此函数最终成为
void func(const A &a)。
以此类推,是否应将void func(int x) 改写为void func(const int &x),以便提高效率?完全没有必要,因为内部数
据类型的参数不存在构造、析构的过程,而复制也非常快,“值传递”和“引用传递”的效率几乎相当。
小结:
1.对于非内部数据类型的输入参数,应该将“值传递”的方式改为“const 引用传递”,目的是提高效率。例如将void func(A a) 改为void func(const A &a)。
2.对于内部数据类型的输入参数,不要将“值传递”的方式改为“const 引用传递”。否则既达不到提高效率的目的,又降低了函数的可理解性。例如void func(int x) 不应该改为void func(const int &x)。
以上解决了两个面试问题:
- 如果函数需要传入一个指针,是否需要为该指针加上const,把const加在指针不同的位置有什么区别;
- 如果写的函数需要传入的参数是一个复杂类型的实例,传入值参数或者引用参数有什么区别,什么时候需要为传入的引用参数加上const。
类中使用const
在一个类中,任何不会修改数据成员的函数都应该声明为const类型。如果在编写const成员函数时,不慎修改 数据成员,或者调用了其它非const成员函数,编译器将指出错误,这无疑会提高程序的健壮性。
使用const关键字进行说明的成员函数,称为常成员函数。只有常成员函数才有资格操作常量或常对象,没有使用const关键字进行说明的成员函数不能用来操作常对象。
对于类中的const成员变量必须通过初始化列表进行初始化,如下所示:
class Apple{
private:
int people[100];
public:
Apple(int i);
const int apple_number;
};
Apple::Apple(int i):apple_number(i)
{
}const对象只能访问const成员函数,而非const对象可以访问任意的成员函数,包括const成员函数.
例如:
//apple.cpp
class Apple
{
private:
int people[100];
public:
Apple(int i);
const int apple_number;
void take(int num) const;
int add(int num);
int add(int num) const;
int getCount() const;
};
//main.cpp
#include<iostream>
#include"apple.cpp"
using namespace std;
Apple::Apple(int i):apple_number(i)
{
}
int Apple::add(int num){
take(num);
}
int Apple::add(int num) const{
take(num);
}
void Apple::take(int num) const
{
cout<<"take func "<<num<<endl;
}
int Apple::getCount() const
{
take(1);
// add(); //error
return apple_number;
}
int main(){
Apple a(2);
cout<<a.getCount()<<endl;
a.add(10);
const Apple b(3);
b.add(100);
return 0;
}编译: g++ -o main main.cpp apple.cpp
结果:
take func 1
2
take func 10
take func 100上面getCount()方法中调用了一个add方法,而add方法并非const修饰,所以运行报错。也就是说const对象只能访问const成员函数。
而add方法又调用了const修饰的take方法,证明了非const对象可以访问任意的成员函数,包括const成员函数。
除此之外,我们也看到add的一个重载函数,也输出了两个结果,说明const对象默认调用const成员函数。
我们除了上述的初始化const常量用初始化列表方式外,也可以通过下面方法:
第一:将常量定义与static结合,也就是:
static const int apple_number第二:在外面初始化:
const int Apple::apple_number=10;当然,如果你使用c++11进行编译,直接可以在定义出初始化,可以直接写成:
static const int apple_number=10;
// 或者
const int apple_number=10;这两种都在c++11中支持!
编译的时候加上-std=c++11即可!
这里提到了static,下面简单的说一下:
在C++中,static静态成员变量不能在类的内部初始化。在类的内部只是声明,定义必须在类定义体的外部,通常在类的实现文件中初始化。
在类中声明:
static int ap;在类实现文件中使用:
int Apple::ap=666对于此项,c++11不能进行声明并初始化,也就是上述使用方法。
static
当与不同类型一起使用时,Static关键字具有不同的含义。我们可以使用static关键字:
静态变量: 函数中的变量,类中的变量
静态类的成员: 类对象和类中的函数
现在让我们详细看一下静态的这些用法:
静态变量
- 函数中的静态变量
当变量声明为static时,空间将在程序的生命周期内分配。即使多次调用该函数,静态变量的空间也只分配一次,前一次调用中的变量值通过下一次函数调用传递。这对于在C / C ++或需要存储先前函数状态的任何其他应用程序非常有用。
#include <iostream>
#include <string>
using namespace std;
void demo()
{
// static variable
static int count = 0;
cout << count << " ";
// value is updated and
// will be carried to next
// function calls
count++;
}
int main()
{
for (int i=0; i<5; i++)
demo();
return 0;
} 输出:
0 1 2 3 4 您可以在上面的程序中看到变量count被声明为static。因此,它的值通过函数调用来传递。每次调用函数时,都不会对变量计数进行初始化。
- 类中的静态变量
由于声明为static的变量只被初始化一次,因为它们在单独的静态存储中分配了空间,因此类中的静态变量**由对象共享。**对于不同的对象,不能有相同静态变量的多个副本。也是因为这个原因,静态变量不能使用构造函数初始化。
#include<iostream>
using namespace std;
class Apple
{
public:
static int i;
Apple()
{
// Do nothing
};
};
int main()
{
Apple obj1;
Apple obj2;
obj1.i =2;
obj2.i = 3;
// prints value of i
cout << obj1.i<<" "<<obj2.i;
} 您可以在上面的程序中看到我们已经尝试为多个对象创建静态变量i的多个副本。但这并没有发生。因此,类中的静态变量应由用户使用类外的类名和范围解析运算符显式初始化,如下所示:
#include<iostream>
using namespace std;
class Apple
{
public:
static int i;
Apple()
{
// Do nothing
};
};
int Apple::i = 1;
int main()
{
Apple obj;
// prints value of i
cout << obj.i;
} 输出:
1静态成员
- 类对象为静态
就像变量一样,对象也在声明为static时具有范围,直到程序的生命周期。
考虑以下程序,其中对象是非静态的。
#include<iostream>
using namespace std;
class Apple
{
int i;
public:
Apple()
{
i = 0;
cout << "Inside Constructor\n";
}
~Apple()
{
cout << "Inside Destructor\n";
}
};
int main()
{
int x = 0;
if (x==0)
{
Apple obj;
}
cout << "End of main\n";
}
输出:
Inside Constructor
Inside Destructor
End of main在上面的程序中,对象在if块内声明为非静态。因此,变量的范围仅在if块内。因此,当创建对象时,将调用构造函数,并且在if块的控制权越过析构函数的同时调用,因为对象的范围仅在声明它的if块内。
如果我们将对象声明为静态,现在让我们看看输出的变化。
#include<iostream>
using namespace std;
class Apple
{
int i;
public:
Apple()
{
i = 0;
cout << "Inside Constructor\n";
}
~Apple()
{
cout << "Inside Destructor\n";
}
};
int main()
{
int x = 0;
if (x==0)
{
static Apple obj;
}
cout << "End of main\n";
}
输出:
Inside Constructor
End of main
Inside Destructor您可以清楚地看到输出的变化。现在,在main结束后调用析构函数。这是因为静态对象的范围是贯穿程序的生命周期。
- 类中的静态函数
就像类中的静态数据成员或静态变量一样,静态成员函数也不依赖于类的对象。我们被允许使用对象和’.'来调用静态成员函数。但建议使用类名和范围解析运算符调用静态成员。
允许静态成员函数仅访问静态数据成员或其他静态成员函数,它们无法访问类的非静态数据成员或成员函数。
#include<iostream>
using namespace std;
class Apple
{
public:
// static member function
static void printMsg()
{
cout<<"Welcome to Apple!";
}
};
// main function
int main()
{
// invoking a static member function
Apple::printMsg();
} 输出:
Welcome to Apple!this
this指针
相信在坐的很多人,都在学Python,对于Python来说有self,类比到C++中就是this指针,那么下面一起来深入分析this指针在类中的使用!
首先来谈谈this指针的用处:
(1)一个对象的this指针并不是对象本身的一部分,不会影响sizeof(对象)的结果。
(2)this作用域是在类内部,当在类的非静态成员函数中访问类的非静态成员的时候,编译器会自动将对象本身的地址作为一个隐含参数传递给函数。也就是说,即使你没有写上this指针,编译器在编译的时候也是加上this的,它作为非静态成员函数的隐含形参,对各成员的访问均通过this进行。
其次,this指针的使用:
(1)在类的非静态成员函数中返回类对象本身的时候,直接使用 return *this。
(2)当参数与成员变量名相同时,如this->n = n (不能写成n = n)。
另外,在网上大家会看到this会被编译器解析成A *const,A const *,究竟是哪一个呢?下面通过断点调试分析:
现有如下例子:
#include<iostream>
#include<cstring>
using namespace std;
class Person{
public:
typedef enum {
BOY = 0,
GIRL
}SexType;
Person(char *n, int a,SexType s){
name=new char[strlen(n)+1];
strcpy(name,n);
age=a;
sex=s;
}
int get_age() const{
return this->age;
}
Person& add_age(int a){
age+=a;
return *this;
}
~Person(){
delete [] name;
}
private:
char * name;
int age;
SexType sex;
};
int main(){
Person p("zhangsan",20,Person::BOY);
cout<<p.get_age()<<endl;
cout<<p.add_age(10).get_age()<<endl;
return 0;
}对于这个简单的程序,相信大家没得问题吧,就是定义了一个类,然后初始化构造函数,并获取这个人的年龄,设置后,再获取!
为了验证this指针是哪一个,现在在add_age处添加断点,运行后如下:
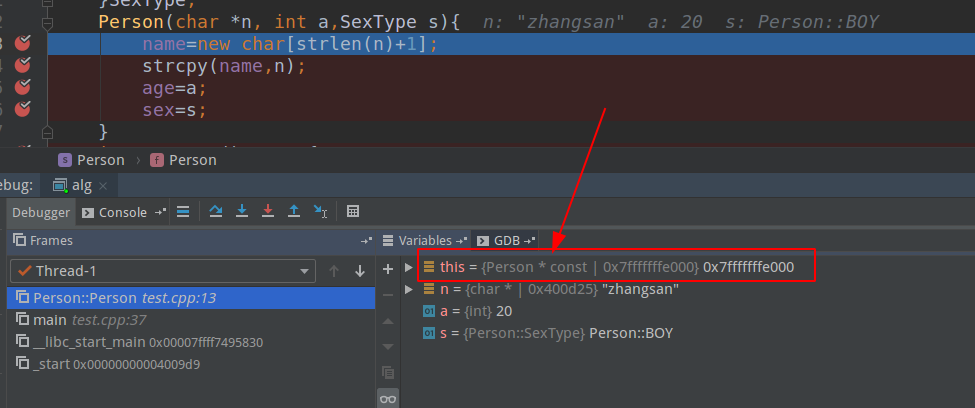
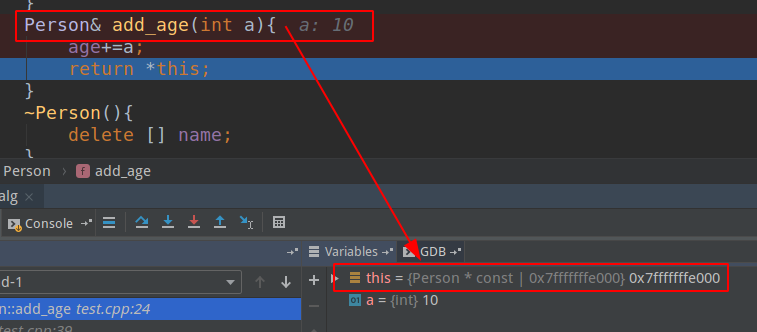
会发现编译器自动为我们加上A* const,而不是A const *this!
紧接着,上述还有个常函数,那么我们在对get_age添加断点,如下:
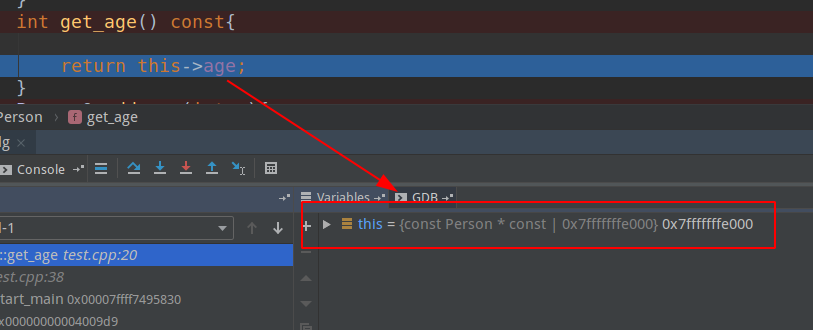
会发现编译器把上述的this,变为const A* const,这个大家也能想到,因为这个函数是const函数,那么针对const函数,它只能访问const变量与const函数,不能修改其他变量的值,所以需要一个this指向不能修改的变量,那就是const A*,又由于本身this是const指针,所以就为const A* const!
总结:this在成员函数的开始执行前构造,在成员的执行结束后清除。上述的get_age函数会被解析成get_age(const A * const this),add_age函数会被解析成add_age(A* const this,int a)。在C++中类和结构是只有一个区别的:类的成员默认是private,而结构是public。this是类的指针,如果换成结构,那this就是结构的指针了。
inline
类中内联
头文件中声明方法
class A
{
public:
void f1(int x);
/**
* @brief 类中定义了的函数是隐式内联函数,声明要想成为内联函数,必须在实现处(定义处)加inline关键字。
*
* @param x
* @param y
*/
void Foo(int x,int y) ///< 定义即隐式内联函数!
{
};
void f1(int x); ///< 声明后,要想成为内联函数,必须在定义处加inline关键字。
};实现文件中定义内联函数:
#include <iostream>
#include "inline.h"
using namespace std;
/**
* @brief inline要起作用,inline要与函数定义放在一起,inline是一种“用于实现的关键字,而不是用于声明的关键字”
*
* @param x
* @param y
*
* @return
*/
int Foo(int x,int y); // 函数声明
inline int Foo(int x,int y) // 函数定义
{
return x+y;
}
// 定义处加inline关键字,推荐这种写法!
inline void A::f1(int x){
}
int main()
{
cout<<Foo(1,2)<<endl;
}
/**
* 编译器对 inline 函数的处理步骤
* 将 inline 函数体复制到 inline 函数调用点处;
* 为所用 inline 函数中的局部变量分配内存空间;
* 将 inline 函数的的输入参数和返回值映射到调用方法的局部变量空间中;
* 如果 inline 函数有多个返回点,将其转变为 inline 函数代码块末尾的分支(使用 GOTO)。
*/
内联能提高函数效率,但并不是所有的函数都定义成内联函数!内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率。
-
如果执行函数体内代码的时间相比于函数调用的开销较大,那么效率的收货会更少!
-
另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
以下情况不宜用内联:
(1)如果函数体内的代码比较长,使得内联将导致内存消耗代价比较高。
(2)如果函数体内出现循环,那么执行函数体内代码的时间要比函数调用的开销大。
虚函数(virtual)可以是内联函数(inline)吗?
- 虚函数可以是内联函数,内联是可以修饰虚函数的,但是当虚函数表现多态性的时候不能内联。
- 内联是在编译期建议编译器内联,而虚函数的多态性在运行期,编译器无法知道运行期调用哪个代码,因此虚函数表现为多态性时(运行期)不可以内联。
inline virtual唯一可以内联的时候是:编译器知道所调用的对象是哪个类(如Base::who()),这只有在编译器具有实际对象而不是对象的指针或引用时才会发生。
#include <iostream>
using namespace std;
class Base
{
public:
inline virtual void who()
{
cout << "I am Base\n";
}
virtual ~Base() {}
};
class Derived : public Base
{
public:
inline void who() // 不写inline时隐式内联
{
cout << "I am Derived\n";
}
};
int main()
{
// 此处的虚函数 who(),是通过类(Base)的具体对象(b)来调用的,编译期间就能确定了,所以它可以是内联的,但最终是否内联取决于编译器。
Base b;
b.who();
// 此处的虚函数是通过指针调用的,呈现多态性,需要在运行时期间才能确定,所以不能为内联。
Base *ptr = new Derived();
ptr->who();
// 因为Base有虚析构函数(virtual ~Base() {}),所以 delete 时,会先调用派生类(Derived)析构函数,再调用基类(Base)析构函数,防止内存泄漏。
delete ptr;
ptr = nullptr;
system("pause");
return 0;
} sizeof
类大小计算
首先来个总结,然后下面给出实际例子,实战!
- 空类的大小为1字节
- 一个类中,虚函数本身、成员函数(包括静态与非静态)和静态数据成员都是不占用类对象的存储空间。
- 对于包含虚函数的类,不管有多少个虚函数,只有一个虚指针,vptr的大小。
- 普通继承,派生类继承了所有基类的函数与成员,要按照字节对齐来计算大小
- 虚函数继承,不管是单继承还是多继承,都是继承了基类的vptr。(32位操作系统4字节,64位操作系统 8字节)!
- 虚继承,继承基类的vptr。
原则1
/**
* @file blackclass.cpp
* @brief 空类的大小为1字节
* @author 光城
* @version v1
* @date 2019-07-21
*/
#include<iostream>
using namespace std;
class A{};
int main()
{
cout<<sizeof(A)<<endl;
return 0;
}原则2
/**
* @file static.cpp
* @brief 静态数据成员
* 静态数据成员被编译器放在程序的一个global data members中,它是类的一个数据成员,但不影响类的大小。不管这个类产生了多少个实例,还是派生了多少新的类,静态数据成员只有一个实例。静态数据成员,一旦被声明,就已经存在。
* @author 光城
* @version v1
* @date 2019-07-21
*/
#include<iostream>
using namespace std;
class A
{
public:
char b;
virtual void fun() {};
static int c;
static int d;
static int f;
};
int main()
{
/**
* @brief 16 字节对齐、静态变量不影响类的大小、vptr指针=8
*/
cout<<sizeof(A)<<endl;
return 0;
}原则3
/**
* @file morevir.cpp
* @brief 对于包含虚函数的类,不管有多少个虚函数,只有一个虚指针,vptr的大小。
* @author 光城
* @version v1
* @date 2019-07-21
*/
#include<iostream>
using namespace std;
class A{
virtual void fun();
virtual void fun1();
virtual void fun2();
virtual void fun3();
};
int main()
{
cout<<sizeof(A)<<endl; // 8
return 0;
}原则4与5
/**
* @file geninhe.cpp
* @brief 1.普通单继承,继承就是基类+派生类自身的大小(注意字节对齐)
* 注意:类的数据成员按其声明顺序加入内存,与访问权限无关,只看声明顺序。
* 2.虚单继承,派生类继承基类vptr
* @author 光城
* @version v1
* @date 2019-07-21
*/
#include<iostream>
using namespace std;
class A
{
public:
char a;
int b;
};
/**
* @brief 此时B按照顺序:
* char a
* int b
* short a
* long b
* 根据字节对齐4+4=8+8+8=24
*/
class B:A
{
public:
short a;
long b;
};
class C
{
A a;
char c;
};
class A1
{
virtual void fun(){}
};
class C1:public A1
{
};
int main()
{
cout<<sizeof(A)<<endl; // 8
cout<<sizeof(B)<<endl; // 24
cout<<sizeof(C)<<endl; // 12
/**
* @brief 对于虚单函数继承,派生类也继承了基类的vptr,所以是8字节
*/
cout<<sizeof(C1)<<endl; // 8
return 0;
}原则6
/**
* @file virnhe.cpp
* @brief 虚继承
* @author 光城
* @version v1
* @date 2019-07-21
*/
#include<iostream>
using namespace std;
class A
{
virtual void fun() {}
};
class B
{
virtual void fun2() {}
};
class C : virtual public A, virtual public B
{
public:
virtual void fun3() {}
};
int main()
{
/**
* @brief 8 8 16 派生类虚继承多个虚函数,会继承所有虚函数的vptr
*/
cout<<sizeof(A)<<" "<<sizeof(B)<<" "<<sizeof(C);
return 0;
}纯虚函数和抽象类
纯虚函数与抽象类
C++中的纯虚函数(或抽象函数)是我们没有实现的虚函数!我们只需声明它! 通过声明中赋值0来声明纯虚函数!
// 抽象类
Class A {
public:
virtual void show() = 0; // 纯虚函数
/* Other members */
}; - 纯虚函数:没有函数体的虚函数
- 抽象类:包含纯虚函数的类
抽象类只能作为基类来派生新类使用,不能创建抽象类的对象,抽象类的指针和引用->由抽象类派生出来的类的对象!
/**
* @brief 抽象类
*/
class Test
{
// Data members of class
public:
// Pure Virtual Function
virtual void show() = 0;
/* Other members */
}; #include<iostream>
using namespace std;
class A
{
private:
int a;
public:
virtual void show()=0; // 纯虚函数
};
int main()
{
/*
* 1. 抽象类只能作为基类来派生新类使用
* 2. 抽象类的指针和引用->由抽象类派生出来的类的对象!
*/
A a; // error 抽象类,不能创建对象
A *a1; // ok 可以定义抽象类的指针
A *a2 = new A(); // error, A是抽象类,不能创建对象
}
实现抽象类
抽象类中:在成员函数内可以调用纯虚函数,在构造函数/析构函数内部不能使用纯虚函数。
如果一个类从抽象类派生而来,它必须实现了基类中的所有纯虚函数,才能成为非抽象类。
// A为抽象类
class A {
public:
virtual void f() = 0; // 纯虚函数
void g(){ this->f(); }
A(){} // 构造函数
};
class B : public A{
public:
void f(){ cout<<"B:f()"<<endl;} // 实现了抽象类的纯虚函数
};重要点
// 抽象类至少包含一个纯虚函数
class Base{
public:
virtual void show() = 0; // 纯虚函数
int getX() { return x; } // 普通成员函数
private:
int x;
}; - 抽象类类型的指针和引用
#include<iostream>
using namespace std;
/**
* @brief 抽象类至少包含一个纯虚函数
*/
class Base
{
int x;
public:
virtual void show() = 0;
int getX() { return x; }
};
class Derived: public Base
{
public:
void show() { cout << "In Derived \n"; }
Derived(){}
};
int main(void)
{
//Base b; //error! 不能创建抽象类的对象
//Base *b = new Base(); error!
Base *bp = new Derived(); // 抽象类的指针和引用 -> 由抽象类派生出来的类的对象
bp->show();
return 0;
} - 如果我们不在派生类中覆盖纯虚函数,那么派生类也会变成抽象类
#include <iostream>
using namespace std;
class Base
{
int x;
public:
virtual void show() = 0;
int getX() { return x; }
};
class Derived: public Base
{
public:
// void show() { }
};
int main(void)
{
Derived d; //error! 派生类没有实现纯虚函数,那么派生类也会变为抽象类,不能创建抽象类的对象
return 0;
} - 抽象类可以有构造函数
#include<iostream>
using namespace std;
// An abstract class with constructor
class Base
{
protected:
int x;
public:
virtual void fun() = 0;
Base(int i) { x = i; }
};
class Derived: public Base
{
int y;
public:
Derived(int i, int j):Base(i) { y = j; }
void fun() { cout << "x = " << x << ", y = " << y; }
};
int main(void)
{
Derived d(4, 5);
d.fun();
return 0;
} - 构造函数不能是虚函数,而析构函数可以是虚析构函数
#include<iostream>
using namespace std;
class Base {
public:
Base() { cout << "Constructor: Base" << endl; }
virtual ~Base() { cout << "Destructor : Base" << endl; }
};
class Derived: public Base {
public:
Derived() { cout << "Constructor: Derived" << endl; }
~Derived() { cout << "Destructor : Derived" << endl; }
};
int main() {
Base *Var = new Derived();
delete Var;
return 0;
}
当基类指针指向派生类对象并删除对象时,我们可能希望调用适当的析构函数。
如果析构函数不是虚拟的,则只能调用基类析构函数。
完整实例
抽象类由派生类继承实现!
#include<iostream>
using namespace std;
class Base
{
int x;
public:
virtual void fun() = 0;
int getX() { return x; }
};
class Derived: public Base
{
int y;
public:
void fun() { cout << "fun() called"; } // 实现了fun()函数
};
int main(void)
{
Derived d;
d.fun();
return 0;
} vptr_vtable
基础理论
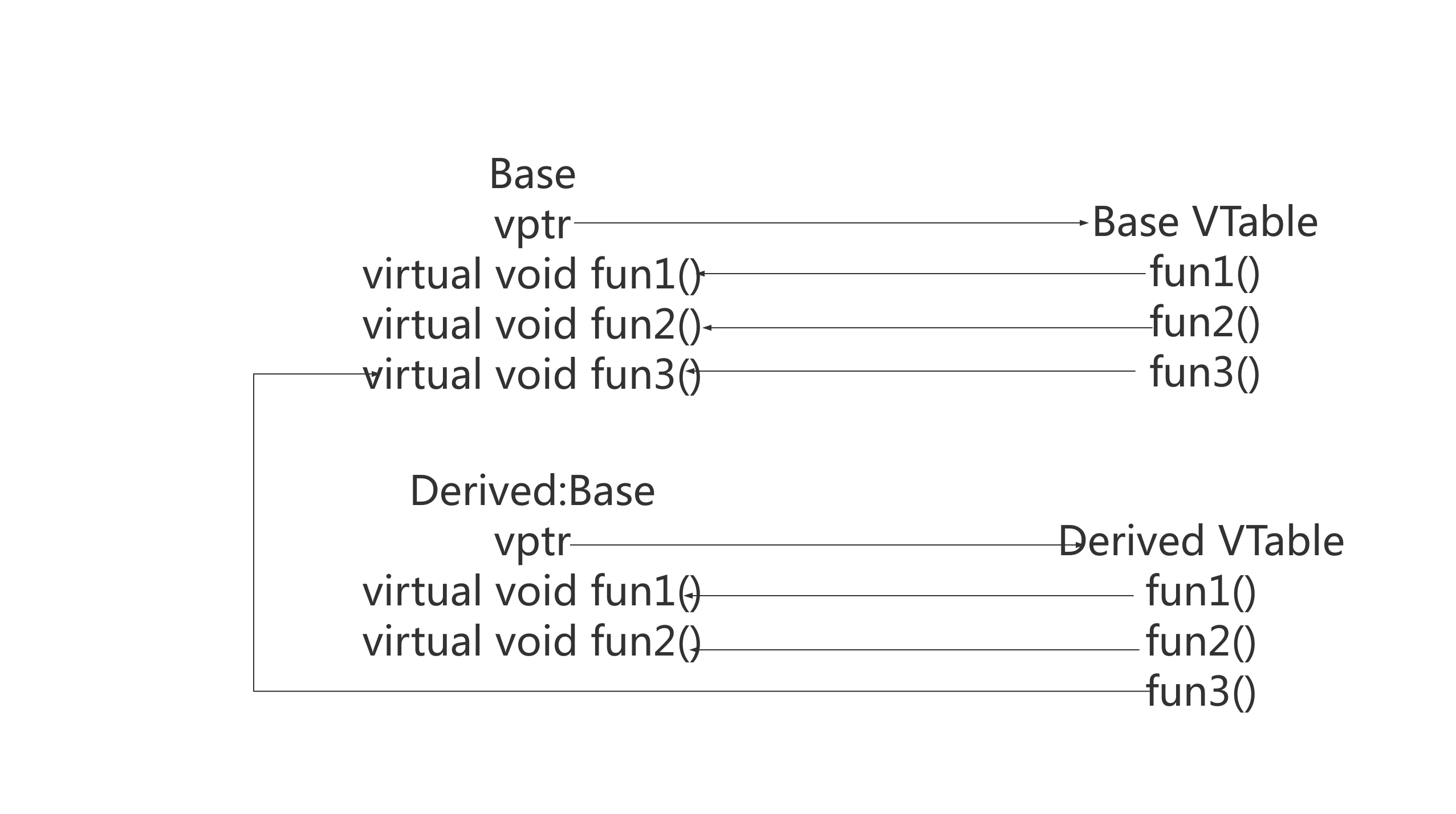
为了实现虚函数,C ++使用一种称为虚拟表的特殊形式的后期绑定。该虚拟表是用于解决在动态/后期绑定方式的函数调用函数的查找表。虚拟表有时会使用其他名称,例如“vtable”,“虚函数表”,“虚方法表”或“调度表”。
虚拟表实际上非常简单,虽然用文字描述有点复杂。首先,每个使用虚函数的类(或者从使用虚函数的类派生)都有自己的虚拟表。该表只是编译器在编译时设置的静态数组。虚拟表包含可由类的对象调用的每个虚函数的一个条目。此表中的每个条目只是一个函数指针,指向该类可访问的派生函数。
其次,编译器还会添加一个隐藏指向基类的指针,我们称之为vptr。vptr在创建类实例时自动设置,以便指向该类的虚拟表。与this指针不同,this指针实际上是编译器用来解析自引用的函数参数,vptr是一个真正的指针。
因此,它使每个类对象的分配大一个指针的大小。这也意味着vptr由派生类继承,这很重要。
实现与内部结构
下面我们来看自动与手动操纵vptr来获取地址与调用虚函数!
开始看代码之前,为了方便大家理解,这里给出调用图:
代码全部遵循标准的注释风格,相信大家看了就会明白,不明白的话,可以留言!
/**
* @file vptr1.cpp
* @brief C++虚函数vptr和vtable
* 编译:g++ -g -o vptr vptr1.cpp -std=c++11
* @author 光城
* @version v1
* @date 2019-07-20
*/
#include <iostream>
#include <stdio.h>
using namespace std;
/**
* @brief 函数指针
*/
typedef void (*Fun)();
/**
* @brief 基类
*/
class Base
{
public:
Base(){};
virtual void fun1()
{
cout << "Base::fun1()" << endl;
}
virtual void fun2()
{
cout << "Base::fun2()" << endl;
}
virtual void fun3(){}
~Base(){};
};
/**
* @brief 派生类
*/
class Derived: public Base
{
public:
Derived(){};
void fun1()
{
cout << "Derived::fun1()" << endl;
}
void fun2()
{
cout << "DerivedClass::fun2()" << endl;
}
~Derived(){};
};
/**
* @brief 获取vptr地址与func地址,vptr指向的是一块内存,这块内存存放的是虚函数地址,这块内存就是我们所说的虚表
*
* @param obj
* @param offset
*
* @return
*/
Fun getAddr(void* obj,unsigned int offset)
{
cout<<"======================="<<endl;
void* vptr_addr = (void *)*(unsigned long *)obj; //64位操作系统,占8字节,通过*(unsigned long *)obj取出前8字节,即vptr指针
printf("vptr_addr:%p\n",vptr_addr);
/**
* @brief 通过vptr指针访问virtual table,因为虚表中每个元素(虚函数指针)在64位编译器下是8个字节,因此通过*(unsigned long *)vptr_addr取出前8字节,
* 后面加上偏移量就是每个函数的地址!
*/
void* func_addr = (void *)*((unsigned long *)vptr_addr+offset);
printf("func_addr:%p\n",func_addr);
return (Fun)func_addr;
}
int main(void)
{
Base ptr;
Derived d;
Base *pt = new Derived(); // 基类指针指向派生类实例
Base &pp = ptr; // 基类引用指向基类实例
Base &p = d; // 基类引用指向派生类实例
cout<<"基类对象直接调用"<<endl;
ptr.fun1();
cout<<"基类对象调用基类实例"<<endl;
pp.fun1();
cout<<"基类指针指向基类实例并调用虚函数"<<endl;
pt->fun1();
cout<<"基类引用指向基类实例并调用虚函数"<<endl;
p.fun1();
// 手动查找vptr 和 vtable
Fun f1 = getAddr(pt, 0);
(*f1)();
Fun f2 = getAddr(pt, 1);
(*f2)();
delete pt;
return 0;
}运行结果:
基类对象直接调用
Base::fun1()
基类引用指向派生类实例
Base::fun1()
基类指针指向派生类实例并调用虚函数
Derived::fun1()
基类引用指向基类实例并调用虚函数
Derived::fun1()
=======================
vptr_addr:0x401130
func_addr:0x400ea8
Derived::fun1()
=======================
vptr_addr:0x401130
func_addr:0x400ed4
DerivedClass::fun2()我们发现C++的动态多态性是通过虚函数来实现的。简单的说,通过virtual函数,指向子类的基类指针可以调用子类的函数。例如,上述通过基类指针指向派生类实例,并调用虚函数,将上述代码简化为:
Base *pt = new Derived(); // 基类指针指向派生类实例
cout<<"基类指针指向派生类实例并调用虚函数"<<endl;
pt->fun1();其过程为:首先程序识别出fun1()是个虚函数,其次程序使用pt->vptr来获取Derived的虚拟表。第三,它查找Derived虚拟表中调用哪个版本的fun1()。这里就可以发现调用的是Derived::fun1()。因此pt->fun1()被解析为Derived::fun1()!
除此之外,上述代码大家会看到,也包含了手动获取vptr地址,并调用vtable中的函数,那么我们一起来验证一下上述的地址与真正在自动调用vtable中的虚函数,比如上述pt->fun1()的时候,是否一致!
这里采用gdb调试,在编译的时候记得加上-g。
通过gdb vptr进入gdb调试页面,然后输入b Derived::fun1对fun1打断点,然后通过输入r运行程序到断点处,此时我们需要查看调用栈中的内存地址,通过disassemable fun1可以查看当前有关fun1中的相关汇编代码,我们看到了0x0000000000400ea8,然后再对比上述的结果会发现与手动调用的fun1一致,fun2类似,以此证明代码正确!
gdb调试信息如下:
(gdb) b Derived::fun1
Breakpoint 1 at 0x400eb4: file vptr1.cpp, line 23.
(gdb) r
Starting program: /home/light/Program/CPlusPlusThings/virtual/pure_virtualAndabstract_class/vptr
基类对象直接调用
Base::fun1()
基类引用指向派生类实例
Base::fun1()
基类指针指向派生类实例并调用虚函数
Breakpoint 1, Derived::fun1 (this=0x614c20) at vptr1.cpp:23
23 cout << "Derived::fun1()" << endl;
(gdb) disassemble fun1
Dump of assembler code for function Derived::fun1():
0x0000000000400ea8 <+0>: push %rbp
0x0000000000400ea9 <+1>: mov %rsp,%rbp
0x0000000000400eac <+4>: sub $0x10,%rsp
0x0000000000400eb0 <+8>: mov %rdi,-0x8(%rbp)
=> 0x0000000000400eb4 <+12>: mov $0x401013,%esi
0x0000000000400eb9 <+17>: mov $0x602100,%edi
0x0000000000400ebe <+22>: callq 0x4009d0 <_ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc@plt>
0x0000000000400ec3 <+27>: mov $0x400a00,%esi
0x0000000000400ec8 <+32>: mov %rax,%rdi
0x0000000000400ecb <+35>: callq 0x4009f0 <_ZNSolsEPFRSoS_E@plt>
0x0000000000400ed0 <+40>: nop
0x0000000000400ed1 <+41>: leaveq
0x0000000000400ed2 <+42>: retq
End of assembler dump.
(gdb) disassemble fun2
Dump of assembler code for function Derived::fun2():
0x0000000000400ed4 <+0>: push %rbp
0x0000000000400ed5 <+1>: mov %rsp,%rbp
0x0000000000400ed8 <+4>: sub $0x10,%rsp
0x0000000000400edc <+8>: mov %rdi,-0x8(%rbp)
0x0000000000400ee0 <+12>: mov $0x401023,%esi
0x0000000000400ee5 <+17>: mov $0x602100,%edi
0x0000000000400eea <+22>: callq 0x4009d0 <_ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc@plt>
0x0000000000400eef <+27>: mov $0x400a00,%esi
0x0000000000400ef4 <+32>: mov %rax,%rdi
0x0000000000400ef7 <+35>: callq 0x4009f0 <_ZNSolsEPFRSoS_E@plt>
0x0000000000400efc <+40>: nop
0x0000000000400efd <+41>: leaveq
0x0000000000400efe <+42>: retq
End of assembler dump.volatile
被 volatile 修饰的变量,在对其进行读写操作时,会引发一些可观测的副作用。而这些可观测的副作用,是由程序之外的因素决定的。
volatile应用
(1)并行设备的硬件寄存器(如状态寄存器)。
假设要对一个设备进行初始化,此设备的某一个寄存器为0xff800000。
int *output = (unsigned int *)0xff800000; //定义一个IO端口;
int init(void)
{
int i;
for(i=0;i< 10;i++)
{
*output = i;
}
}经过编译器优化后,编译器认为前面循环半天都是废话,对最后的结果毫无影响,因为最终只是将output这个指针赋值为 9,所以编译器最后给你编译编译的代码结果相当于:
int init(void)
{
*output = 9;
}如果你对此外部设备进行初始化的过程是必须是像上面代码一样顺序的对其赋值,显然优化过程并不能达到目的。反之如果你不是对此端口反复写操作,而是反复读操作,其结果是一样的,编译器在优化后,也许你的代码对此地址的读操作只做了一次。然而从代码角度看是没有任何问题的。这时候就该使用volatile通知编译器这个变量是一个不稳定的,在遇到此变量时候不要优化。
(2)一个中断服务子程序中访问到的变量;
static int i=0;
int main()
{
while(1)
{
if(i) dosomething();
}
}
/* Interrupt service routine */
void IRS()
{
i=1;
}上面示例程序的本意是产生中断时,由中断服务子程序IRS响应中断,变更程序变量i,使在main函数中调用dosomething函数,但是,由于编译器判断在main函数里面没有修改过i,因此可能只执行一次对从i到某寄存器的读操作,然后每次if判断都只使用这个寄存器里面的“i副本”,导致dosomething永远不会被调用。如果将变量i加上volatile修饰,则编译器保证对变量i的读写操作都不会被优化,从而保证了变量i被外部程序更改后能及时在原程序中得到感知。
(3)多线程应用中被多个任务共享的变量。
当多个线程共享某一个变量时,该变量的值会被某一个线程更改,应该用 volatile 声明。作用是防止编译器优化把变量从内存装入CPU寄存器中,当一个线程更改变量后,未及时同步到其它线程中导致程序出错。volatile的意思是让编译器每次操作该变量时一定要从内存中真正取出,而不是使用已经存在寄存器中的值。示例如下:
volatile bool bStop=false; //bStop 为共享全局变量
//第一个线程
void threadFunc1()
{
...
while(!bStop){...}
}
//第二个线程终止上面的线程循环
void threadFunc2()
{
...
bStop = true;
}要想通过第二个线程终止第一个线程循环,如果bStop不使用volatile定义,那么这个循环将是一个死循环,因为bStop已经读取到了寄存器中,寄存器中bStop的值永远不会变成FALSE,加上volatile,程序在执行时,每次均从内存中读出bStop的值,就不会死循环了。
是否了解volatile的应用场景是区分C/C++程序员和嵌入式开发程序员的有效办法,搞嵌入式的家伙们经常同硬件、中断、RTOS等等打交道,这些都要求用到volatile变量,不懂得volatile将会带来程序设计的灾难。
volatile常见问题
下面的问题可以看一下面试者是不是直正了解volatile。
(1)一个参数既可以是const还可以是volatile吗?为什么?
可以。一个例子是只读的状态寄存器。它是volatile因为它可能被意想不到地改变。它是const因为程序不应该试图去修改它。
(2)一个指针可以是volatile吗?为什么?
可以。尽管这并不常见。一个例子是当一个中断服务子程序修该一个指向一个buffer的指针时。
(3)下面的函数有什么错误?
int square(volatile int *ptr)
{
return *ptr * *ptr;
} 这段代码有点变态,其目的是用来返回指针ptr指向值的平方,但是,由于ptr指向一个volatile型参数,编译器将产生类似下面的代码:
int square(volatile int *ptr)
{
int a,b;
a = *ptr;
b = *ptr;
return a * b;
} 由于*ptr的值可能被意想不到地改变,因此a和b可能是不同的。结果,这段代码可能返回的不是你所期望的平方值!正确的代码如下:
long square(volatile int *ptr)
{
int a=*ptr;
return a * a;
} volatile使用
-
volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素(操作系统、硬件、其它线程等)更改。所以使用 volatile 告诉编译器不应对这样的对象进行优化。
-
volatile 关键字声明的变量,每次访问时都必须从内存中取出值(没有被 volatile 修饰的变量,可能由于编译器的优化,从 CPU 寄存器中取值)
-
const 可以是 volatile (如只读的状态寄存器)
-
指针可以是 volatile
代码学习:
/* Compile code without optimization option */
#include <stdio.h>
int main(void)
{
const int local = 10;
int *ptr = (int*) &local;
printf("Initial value of local : %d \n", local);
*ptr = 100;
printf("Modified value of local: %d \n", local);
return 0;
} /* Compile code with optimization option */
#include <stdio.h>
int main(void)
{
const volatile int local = 10;
int *ptr = (int*) &local;
printf("Initial value of local : %d \n", local);
*ptr = 100;
printf("Modified value of local: %d \n", local);
return 0;
}
assert
第一个断言案例
断言,是宏,而非函数。
assert 宏的原型定义在 <assert.h>(C)、
可以通过定义 NDEBUG 来关闭 assert,但是需要在源代码的开头,include <assert.h> 之前。
void assert(int expression);#include <stdio.h>
#include <assert.h>
int main()
{
int x = 7;
/* Some big code in between and let's say x
is accidentally changed to 9 */
x = 9;
// Programmer assumes x to be 7 in rest of the code
assert(x==7);
/* Rest of the code */
return 0;
} 输出:
assert: assert.c:13: main: Assertion 'x==7' failed.可以看到输出会把源码文件,行号错误位置,提示出来!
断言与正常错误处理
- 断言主要用于检查逻辑上不可能的情况。
例如,它们可用于检查代码在开始运行之前所期望的状态,或者在运行完成后检查状态。与正常的错误处理不同,断言通常在运行时被禁用。
- 忽略断言,在代码开头加上:
#define NDEBUG // 加上这行,则 assert 不可用# define NDEBUG // 忽略断言
#include<assert.h>
int main(){
int x=7;
assert(x==5);
return 0;
}位域
Bit field 是什么?
“ 位域 “ 或 “ 位段 “(Bit field)为一种数据结构,可以把数据以位的形式紧凑的储存,并允许程序员对此结构的位进行操作。这种数据结构的一个好处是它可以使数据单元节省储存空间,当程序需要成千上万个数据单元时,这种方法就显得尤为重要。第二个好处是位段可以很方便的访问一个整数值的部分内容从而可以简化程序源代码。而这种数据结构的缺点在于,位段实现依赖于具体的机器和系统,在不同的平台可能有不同的结果,这导致了位段在本质上是不可移植的。
- 位域在内存中的布局是与机器有关的
- 位域的类型必须是整型或枚举类型,带符号类型中的位域的行为将因具体实现而定
- 取地址运算符(&)不能作用于位域,任何指针都无法指向类的位域
位域使用
位域通常使用结构体声明, 该结构声明为每个位域成员设置名称,并决定其宽度:
struct bit_field_name
{
type member_name : width;
};| Elements | Description |
|---|---|
| bit_field_name | 位域结构名 |
| type | 位域成员的类型,必须为 int、signed int 或者 unsigned int 类型 |
| member_name | 位域成员名 |
| width | 规定成员所占的位数 |
例如声明如下一个位域:
struct _PRCODE
{
unsigned int code1: 2;
unsigned int cdde2: 2;
unsigned int code3: 8;
};
struct _PRCODE prcode;该定义使 prcode包含 2 个 2 Bits 位域和 1 个 8 Bits 位域,我们可以使用结构体的成员运算符对其进行赋值
prcode.code1 = 0;
prcode.code2 = 3;
procde.code3 = 102;赋值时要注意值的大小不能超过位域成员的容量,例如 prcode.code3 为 8 Bits 的位域成员,其容量为 2^8 = 256,即赋值范围应为 [0,255]。
位域的大小和对齐
位域的大小
例如以下位域:
struct box
{
unsigned int a: 1;
unsigned int : 3;
unsigned int b: 4;
};该位域结构体中间有一个未命名的位域,占据 3 Bits,仅起填充作用,并无实际意义。 填充使得该结构总共使用了 8 Bits。但 C 语言使用 unsigned int 作为位域的基本单位,即使一个结构的唯一成员为 1 Bit 的位域,该结构大小也和一个 unsigned int 大小相同。 有些系统中,unsigned int 为 16 Bits,在 x86 系统中为 32 Bits。文章以下均默认 unsigned int 为 32 Bits。
位域的对齐
一个位域成员不允许跨越两个 unsigned int 的边界,如果成员声明的总位数超过了一个 unsigned int 的大小, 那么编辑器会自动移位位域成员,使其按照 unsigned int 的边界对齐。
例如:
struct stuff
{
unsigned int field1: 30;
unsigned int field2: 4;
unsigned int field3: 3;
};field1 + field2 = 34 Bits,超出 32 Bits, 编译器会将field2移位至下一个 unsigned int 单元存放, stuff.field1 和 stuff.field2 之间会留下一个 2 Bits 的空隙, stuff.field3 紧跟在 stuff.field2 之后,该结构现在大小为 2 * 32 = 64 Bits。
这个空洞可以用之前提到的未命名的位域成员填充,我们也可以使用一个宽度为 0 的未命名位域成员令下一位域成员与下一个整数对齐。
例如:
struct stuff
{
unsigned int field1: 30;
unsigned int : 2;
unsigned int field2: 4;
unsigned int : 0;
unsigned int field3: 3;
};这里 stuff.field1 与 stuff.field2 之间有一个 2 Bits 的空隙,stuff.field3 则存储在下一个 unsigned int 中,该结构现在大小为 3 * 32 = 96 Bits。
学习代码见:
#include<iostream>
using namespace std;
struct stuff
{
unsigned int field1: 30;
unsigned int : 2;
unsigned int field2: 4;
unsigned int : 0;
unsigned int field3: 3;
};
int main(){
struct stuff s={1,3,5};
cout<<s.field1<<endl;
cout<<s.field2<<endl;
cout<<s.field3<<endl;
cout<<sizeof(s)<<endl;
return 0;
}
位域的初始化和位的重映射
初始化
位域的初始化与普通结构体初始化的方法相同,这里列举两种,如下:
struct stuff s1= {20,8,6};或者直接为位域成员赋值
struct stuff s1;
s1.field1 = 20;
s1.field2 = 8;
s1.field3 = 4;位域的重映射 (Re-mapping)
声明一个 大小为 32 Bits 的位域
struct box {
unsigned int ready: 2;
unsigned int error: 2;
unsigned int command: 4;
unsigned int sector_no: 24;
}b1;利用重映射将位域归零
int* p = (int *) &b1; // 将 "位域结构体的地址" 映射至 "整形(int*) 的地址"
*p = 0; // 清除 s1,将各成员归零利用联合 (union) 将 32 Bits 位域 重映射至 unsigned int 型
先简单介绍一下联合
“联合” 是一种特殊的类,也是一种构造类型的数据结构。在一个 “联合” 内可以定义多种不同的数据类型, 一个被说明为该 “联合” 类型的变量中,允许装入该 “联合” 所定义的任何一种数据,这些数据共享同一段内存,以达到节省空间的目的
“联合” 与 “结构” 有一些相似之处。但两者有本质上的不同。在结构中各成员有各自的内存空间, 一个结构变量的总长度是各成员长度之和(空结构除外,同时不考虑边界调整)。而在 “联合” 中,各成员共享一段内存空间, 一个联合变量的长度等于各成员中最长的长度。应该说明的是, 这里所谓的共享不是指把多个成员同时装入一个联合变量内, 而是指该联合变量可被赋予任一成员值,但每次只能赋一种值, 赋入新值则冲去旧值。
我们可以声明以下联合:
union u_box {
struct box st_box;
unsigned int ui_box;
};x86 系统中 unsigned int 和 box 都为 32 Bits, 通过该联合使 st_box 和 ui_box 共享一块内存。具体位域中哪一位与 unsigned int 哪一位相对应,取决于编译器和硬件。
利用联合将位域归零,代码如下:
union u_box u;
u.ui_box = 0;extern
C++与C编译区别
在C中常在头文件见到extern "C"修饰函数,那有什么作用呢? 是用于C链接在C语言模块中定义的函数。
C虽然兼容C,但C文件中函数编译后生成的符号与C语言生成的不同。因为C支持函数重载,C函数编译后生成的符号带有函数参数类型的信息,而C则没有。
例如int add(int a, int b)函数经过C编译器生成.o文件后,add会变成形如add_int_int之类的, 而C的话则会是形如_add, 就是说:相同的函数,在C和C中,编译后生成的符号不同。
这就导致一个问题:如果C中使用C语言实现的函数,在编译链接的时候,会出错,提示找不到对应的符号。此时extern "C"就起作用了:告诉链接器去寻找_add这类的C语言符号,而不是经过C修饰的符号。
C++调用C函数
C++调用C函数的例子: 引用C的头文件时,需要加extern "C"
//add.h
#ifndef ADD_H
#define ADD_H
int add(int x,int y);
#endif
//add.c
#include "add.h"
int add(int x,int y) {
return x+y;
}
//add.cpp
#include <iostream>
#include "add.h"
using namespace std;
int main() {
add(2,3);
return 0;
}编译:
//Generate add.o file
gcc -c add.c链接:
g++ add.cpp add.o -o main没有添加extern “C” 报错:
> g++ add.cpp add.o -o main
add.o:在函数‘main’中:
add.cpp:(.text+0x0): `main'被多次定义
/tmp/ccH65yQF.o:add.cpp:(.text+0x0):第一次在此定义
/tmp/ccH65yQF.o:在函数‘main’中:
add.cpp:(.text+0xf):对‘add(int, int)’未定义的引用
add.o:在函数‘main’中:
add.cpp:(.text+0xf):对‘add(int, int)’未定义的引用
collect2: error: ld returned 1 exit status添加extern "C"后:
add.cpp
#include <iostream>
using namespace std;
extern "C" {
#include "add.h"
}
int main() {
add(2,3);
return 0;
}编译的时候一定要注意,先通过gcc生成中间文件add.o。
gcc -c add.c 然后编译:
g++ add.cpp add.o -o main而通常为了C代码能够通用,即既能被C调用,又能被C++调用,头文件通常会有如下写法:
#ifdef __cplusplus
extern "C"{
#endif
int add(int x,int y);
#ifdef __cplusplus
}
#endif即在C调用该接口时,会以C接口的方式调用。这种方式使得C者不需要额外的extern C,而标准库头文件通常也是类似的做法,否则你为何不需要extern C就可以直接使用stdio.h中的C函数呢?
C中调用C++函数
extern "C"在C中是语法错误,需要放在C++头文件中。
// add.h
#ifndef ADD_H
#define ADD_H
extern "C" {
int add(int x,int y);
}
#endif
// add.cpp
#include "add.h"
int add(int x,int y) {
return x+y;
}
// add.c
extern int add(int x,int y);
int main() {
add(2,3);
return 0;
}编译:
g++ -c add.cpp链接:
gcc add.c add.o -o main上述案例源代码见:
综上,总结出使用方法,在C语言的头文件中,对其外部函数只能指定为extern类型,C语言中不支持extern "C"声明,在.c文件中包含了extern "C"时会出现编译语法错误。所以使用extern "C"全部都放在于cpp程序相关文件或其头文件中。
总结出如下形式:
(1)C++调用C函数:
//xx.h
extern int add(...)
//xx.c
int add(){
}
//xx.cpp
extern "C" {
#include "xx.h"
}(2)C调用C++函数
//xx.h
extern "C"{
int add();
}
//xx.cpp
int add(){
}
//xx.c
extern int add();不过与C调用C接口不同,C确实是能够调用编译好的C函数,而这里C调用C++,不过是把C代码当成C代码编译后调用而已。也就是说,C并不能直接调用C库函数。
struct
C中struct
- 在C中struct只单纯的用作数据的复合类型,也就是说,在结构体声明中只能将数据成员放在里面,而不能将函数放在里面。
- 在C结构体声明中不能使用C访问修饰符,如:public、protected、private 而在C中可以使用。
- 在C中定义结构体变量,如果使用了下面定义必须加struct。
- C的结构体不能继承(没有这一概念)。
- 若结构体的名字与函数名相同,可以正常运行且正常的调用!例如:可以定义与 struct Base 不冲突的 void Base() {}。
完整案例:
#include<stdio.h>
struct Base { // public
int v1;
// public: //error
int v2;
//private:
int v3;
//void print(){ // c中不能在结构体中嵌入函数
// printf("%s\n","hello world");
//}; //error!
};
void Base(){
printf("%s\n","I am Base func");
}
//struct Base base1; //ok
//Base base2; //error
int main() {
struct Base base;
base.v1=1;
//base.print();
printf("%d\n",base.v1);
Base();
return 0;
}最后输出:
1
I am Base funcC++中struct
与C对比如下:
- C++结构体中不仅可以定义数据,还可以定义函数。
- C++结构体中可以使用访问修饰符,如:public、protected、private 。
- C++结构体使用可以直接使用不带struct。
- C++继承
- 若结构体的名字与函数名相同,可以正常运行且正常的调用!但是定义结构体变量时候只用用带struct的!
例如:
情形1:不适用typedef定义结构体别名
未添加同名函数前:
struct Student {
};
Student(){}
Struct Student s; //ok
Student s; //ok添加同名函数后:
struct Student {
};
Student(){}
Struct Student s; //ok
Student s; //error情形二:使用typedef定义结构体别名
typedef struct Base1 {
int v1;
// private: //error!
int v3;
public: //显示声明public
int v2;
void print(){
printf("%s\n","hello world");
};
}B;
//void B() {} //error! 符号 "B" 已经被定义为一个 "struct Base1" 的别名前三种案例
#include<iostream>
#include<stdio.h>
struct Base {
int v1;
// private: //error!
int v3;
public: //显示声明public
int v2;
void print(){
printf("%s\n","hello world");
};
};
int main() {
struct Base base1; //ok
Base base2; //ok
Base base;
base.v1=1;
base.v3=2;
base.print();
printf("%d\n",base.v1);
printf("%d\n",base.v3);
return 0;
}继承案例
#include<iostream>
#include<stdio.h>
struct Base {
int v1;
// private: //error!
int v3;
public: //显示声明public
int v2;
virtual void print(){
printf("%s\n","Base");
};
};
struct Derived:Base {
public:
int v2;
void print(){
printf("%s\n","Derived");
};
};
int main() {
Base *b=new Derived();
b->print();
return 0;
}同名函数
#include<iostream>
#include<stdio.h>
struct Base {
int v1;
// private: //error!
int v3;
public: //显示声明public
int v2;
void print(){
printf("%s\n","hello world");
};
};
typedef struct Base1 {
int v1;
// private: //error!
int v3;
public: //显示声明public
int v2;
void print(){
printf("%s\n","hello world");
};
}B;
void Base(){
printf("%s\n","I am Base func");
}
//void B() {} //error! 符号 "B" 已经被定义为一个 "struct Base1" 的别名
int main() {
struct Base base; //ok
//Base base1; // error!
base.v1=1;
base.v3=2;
base.print();
printf("%d\n",base.v1);
printf("%d\n",base.v3);
Base();
return 0;
}总结
C和C++中的Struct区别
| C | C++ |
|---|---|
| 不能将函数放在结构体声明 | 能将函数放在结构体声明 |
| 在C结构体声明中不能使用C++访问修饰符。 | public、protected、private 在C++中可以使用。 |
| 在C中定义结构体变量,如果使用了下面定义必须加struct。 | 可以不加struct |
| 结构体不能继承(没有这一概念)。 | 可以继承 |
| 若结构体的名字与函数名相同,可以正常运行且正常的调用! | 若结构体的名字与函数名相同,使用结构体,只能使用带struct定义! |
struct 与 class
总的来说,struct 更适合看成是一个数据结构的实现体,class 更适合看成是一个对象的实现体。
区别:
最本质的一个区别就是默认的访问控制
默认的继承访问权限。struct 是 public 的,class 是 private 的。
struct 作为数据结构的实现体,它默认的数据访问控制是 public 的,而 class 作为对象的实现体,它默认的成员变量访问控制是 private 的。
union
联合(union)是一种节省空间的特殊的类,一个 union 可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。当某个成员被赋值后其他成员变为未定义状态。联合有如下特点:
- 默认访问控制符为 public
- 可以含有构造函数、析构函数
- 不能含有引用类型的成员
- 不能继承自其他类,不能作为基类
- 不能含有虚函数
- 匿名 union 在定义所在作用域可直接访问 union 成员
- 匿名 union 不能包含 protected 成员或 private 成员
- 全局匿名联合必须是静态(static)的
#include<iostream>
/**
* 默认访问控制符为public
*/
union UnionTest {
/**
* 可以含有构造函数、析构函数
*/
UnionTest() : i(10) {print(i);};
~UnionTest(){};
int i;
private:
void print(int i){std::cout<<i<<std::endl;};
};
/**
* 全局匿名联合必须是静态的
*/
static union {
int i;
double d;
};
int main() {
UnionTest u;
union {
int i;
double d;
};
std::cout << u.i << std::endl; // 输出 UnionTest 联合的 10
::i = 20;
std::cout << ::i << std::endl; // 输出全局静态匿名联合的 20
/**
* 匿名union在定义所在作用域可直接访问union成员
*/
i = 30;
std::cout << i << std::endl; // 输出局部匿名联合的 30
return 0;
}
C 实现 C++ 多态
C++实现案例
C中的多态:在C中会维护一张虚函数表,根据赋值兼容规则,我们知道父类的指针或者引用是可以指向子类对象的。
如果一个父类的指针或者引用调用父类的虚函数则该父类的指针会在自己的虚函数表中查找自己的函数地址,如果该父类对象的指针或者引用指向的是子类的对象,而且该子类已经重写了父类的虚函数,则该指针会调用子类的已经重写的虚函数。
#include <iostream>
using namespace std;
class A
{
public:
virtual void f()//虚函数实现
{
cout << "Base A::f() " << endl;
}
};
class B:public A // 必须为共有继承,否则后面调用不到,class默认为私有继承!
{
public:
virtual void f()//虚函数实现,子类中virtual关键字可以没有
{
cout << "Derived B::f() " << endl;
}
};
int main()
{
A a;//基类对象
B b;//派生类对象
A* pa = &a;//父类指针指向父类对象
pa->f();//调用父类的函数
pa = &b; //父类指针指向子类对象,多态实现
pa->f();//调用派生类同名函数
return 0;
}
C实现
- 封装
C语言中是没有class类这个概念的,但是有struct结构体,我们可以考虑使用struct来模拟;
使用函数指针把属性与方法封装到结构体中。
- 继承
结构体嵌套
- 多态
类与子类方法的函数指针不同
在C语言的结构体内部是没有成员函数的,如果实现这个父结构体和子结构体共有的函数呢?我们可以考虑使用函数指针来模拟。但是这样处理存在一个缺陷就是:父子各自的函数指针之间指向的不是类似C++中维护的虚函数表而是一块物理内存,如果模拟的函数过多的话就会不容易维护了。
模拟多态,必须保持函数指针变量对齐(在内容上完全一致,而且变量对齐上也完全一致)。否则父类指针指向子类对象,运行崩溃!
#include <stdio.h>
/// 重定义一个函数指针类型
typedef void (*pf) ();
/**
* @brief 父类
*/
typedef struct _A
{
pf _f;
}A;
/**
* @brief 子类
*/
typedef struct _B
{
A _b; ///< 在子类中定义一个基类的对象即可实现对父类的继承。
}B;
void FunA()
{
printf("%s\n","Base A::fun()");
}
void FunB()
{
printf("%s\n","Derived B::fun()");
}
int main()
{
A a;
B b;
a._f = FunA;
b._b._f = FunB;
A *pa = &a;
pa->_f();
pa = (A *)&b; /// 让父类指针指向子类的对象,由于类型不匹配所以要进行强转
pa->_f();
return 0;
}explict
- explicit 修饰构造函数时,可以防止隐式转换和复制初始化
- explicit 修饰转换函数时,可以防止隐式转换,但按语境转换除外
#include <iostream>
using namespace std;
struct A
{
A(int) { }
operator bool() const { return true; }
};
struct B
{
explicit B(int) {}
explicit operator bool() const { return true; }
};
void doA(A a) {}
void doB(B b) {}
int main()
{
A a1(1); // OK:直接初始化
A a2 = 1; // OK:复制初始化
A a3{ 1 }; // OK:直接列表初始化
A a4 = { 1 }; // OK:复制列表初始化
A a5 = (A)1; // OK:允许 static_cast 的显式转换
doA(1); // OK:允许从 int 到 A 的隐式转换
if (a1); // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a6(a1); // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a7 = a1; // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a8 = static_cast<bool>(a1); // OK :static_cast 进行直接初始化
B b1(1); // OK:直接初始化
// B b2 = 1; // 错误:被 explicit 修饰构造函数的对象不可以复制初始化
B b3{ 1 }; // OK:直接列表初始化
// B b4 = { 1 }; // 错误:被 explicit 修饰构造函数的对象不可以复制列表初始化
B b5 = (B)1; // OK:允许 static_cast 的显式转换
// doB(1); // 错误:被 explicit 修饰构造函数的对象不可以从 int 到 B 的隐式转换
if (b1); // OK:被 explicit 修饰转换函数 B::operator bool() 的对象可以从 B 到 bool 的按语境转换
bool b6(b1); // OK:被 explicit 修饰转换函数 B::operator bool() 的对象可以从 B 到 bool 的按语境转换
// bool b7 = b1; // 错误:被 explicit 修饰转换函数 B::operator bool() 的对象不可以隐式转换
bool b8 = static_cast<bool>(b1); // OK:static_cast 进行直接初始化
return 0;
}
参考链接:
https://stackoverflow.com/questions/4600295/what-is-the-meaning-of-operator-bool-const
friend
概述
友元提供了一种 普通函数或者类成员函数 访问另一个类中的私有或保护成员 的机制。也就是说有两种形式的友元:
(1)友元函数:普通函数对一个访问某个类中的私有或保护成员。
(2)友元类:类A中的成员函数访问类B中的私有或保护成员
优点:提高了程序的运行效率。
缺点:破坏了类的封装性和数据的透明性。
总结:
- 能访问私有成员
- 破坏封装性
- 友元关系不可传递
- 友元关系的单向性
- 友元声明的形式及数量不受限制
友元函数
在类声明的任何区域中声明,而定义则在类的外部。
friend <类型><友元函数名>(<参数表>);注意,友元函数只是一个普通函数,并不是该类的类成员函数,它可以在任何地方调用,友元函数中通过对象名来访问该类的私有或保护成员。
#include <iostream>
using namespace std;
class A
{
public:
A(int _a):a(_a){};
friend int geta(A &ca); ///< 友元函数
private:
int a;
};
int geta(A &ca)
{
return ca.a;
}
int main()
{
A a(3);
cout<<geta(a)<<endl;
return 0;
}友元类
友元类的声明在该类的声明中,而实现在该类外。
friend class <友元类名>;类B是类A的友元,那么类B可以直接访问A的私有成员。
#include <iostream>
using namespace std;
class A
{
public:
A(int _a):a(_a){};
friend class B;
private:
int a;
};
class B
{
public:
int getb(A ca) {
return ca.a;
};
};
int main()
{
A a(3);
B b;
cout<<b.getb(a)<<endl;
return 0;
}注意
-
友元关系没有继承性
假如类B是类A的友元,类C继承于类A,那么友元类B是没办法直接访问类C的私有或保护成员。 -
友元关系没有传递性
假如类B是类A的友元,类C是类B的友元,那么友元类C是没办法直接访问类A的私有或保护成员,也就是不存在“友元的友元”这种关系。
using
基本使用
局部与全局using,具体操作与使用见下面案例:
#include <iostream>
#define isNs1 1
//#define isGlobal 2
using namespace std;
void func()
{
cout<<"::func"<<endl;
}
namespace ns1 {
void func()
{
cout<<"ns1::func"<<endl;
}
}
namespace ns2 {
#ifdef isNs1
using ns1::func; /// ns1中的函数
#elif isGlobal
using ::func; /// 全局中的函数
#else
void func()
{
cout<<"other::func"<<endl;
}
#endif
}
int main()
{
/**
* 这就是为什么在c++中使用了cmath而不是math.h头文件
*/
ns2::func(); // 会根据当前环境定义宏的不同来调用不同命名空间下的func()函数
return 0;
}改变访问性
class Base{
public:
std::size_t size() const { return n; }
protected:
std::size_t n;
};
class Derived : private Base {
public:
using Base::size;
protected:
using Base::n;
};类Derived私有继承了Base,对于它来说成员变量n和成员函数size都是私有的,如果使用了using语句,可以改变他们的可访问性,如上述例子中,size可以按public的权限访问,n可以按protected的权限访问。
#include <iostream>
using namespace std;
class Base1 {
public:
Base1():value(10) {}
virtual ~Base1() {}
void test1() { cout << "Base test1..." << endl; }
protected: // 保护
int value;
};
// 默认为私有继承
class Derived1 : Base1 {
public:
void test2() { cout << "value is " << value << endl; }
};
class Base {
public:
Base():value(20) {}
virtual ~Base() {}
void test1() { cout << "Base test1..." << endl; }
private: //私有
int value;
};
/**
* 子类对父类成员的访问权限跟如何继承没有任何关系,
* “子类可以访问父类的public和protected成员,不可以访问父类的private成员”——这句话对任何一种继承都是成立的。
*
*/
class Derived : Base {
public:
using Base::value;
void test2() { cout << "value is " << value << endl; }
};
int main()
{
Derived1 d1;
d1.test2();
Derived d;
d.test2();
return 0;
}
函数重载
在继承过程中,派生类可以覆盖重载函数的0个或多个实例,一旦定义了一个重载版本,那么其他的重载版本都会变为不可见。
如果对于基类的重载函数,我们需要在派生类中修改一个,又要让其他的保持可见,必须要重载所有版本,这样十分的繁琐。
#include <iostream>
using namespace std;
class Base{
public:
void f(){ cout<<"f()"<<endl;
}
void f(int n){
cout<<"Base::f(int)"<<endl;
}
};
class Derived : private Base {
public:
using Base::f;
void f(int n){
cout<<"Derived::f(int)"<<endl;
}
};
int main()
{
Base b;
Derived d;
d.f();
d.f(1);
return 0;
}如上代码中,在派生类中使用using声明语句指定一个名字而不指定形参列表,所以一条基类成员函数的using声明语句就可以把该函数的所有重载实例添加到派生类的作用域中。此时,派生类只需要定义其特有的函数就行了,而无需为继承而来的其他函数重新定义。
取代typedef
C中常用typedef A B这样的语法,将B定义为A类型,也就是给A类型一个别名B
对应typedef A B,使用using B=A可以进行同样的操作。
#include <iostream>
#include <vector>
using namespace std;
typedef vector<int> V1;
using V2 = vector<int>;
int main()
{
int nums1[] = {1,2,3,4,5,6};
V1 vec1(nums1,nums1+sizeof(nums1)/sizeof(int));
int nums2[] = {5,7,6};
V2 vec2(nums2,nums2+sizeof(nums2)/sizeof(int));
for(auto i:vec1)
cout<<i<<" ";
cout<<endl;
for(auto i:vec2)
cout<<i<<" ";
cout<<endl;
return 0;
}: :
- 全局作用域符(::name):用于类型名称(类、类成员、成员函数、变量等)前,表示作用域为全局命名空间
- 类作用域符(class::name):用于表示指定类型的作用域范围是具体某个类的
- 命名空间作用域符(namespace::name):用于表示指定类型的作用域范围是具体某个命名空间的
#include <iostream>
using namespace std;
int count=0; // 全局(::)的count
class A {
public:
static int count; // 类A的count (A::count)
};
// 静态变量必须在此处定义
int A::count;
int main() {
::count=1; // 设置全局的count为1
A::count=5; // 设置类A的count为2
cout<<A::count<<endl;
// int count=3; // 局部count
// count=4; // 设置局部的count为4
return 0;
}enum
传统行为
枚举有如下问题:
- 作用域不受限,会容易引起命名冲突。例如下面无法编译通过的:
#include <iostream>
using namespace std;
enum Color {RED,BLUE};
enum Feeling {EXCITED,BLUE};
int main()
{
return 0;
}- 会隐式转换为int
- 用来表征枚举变量的实际类型不能明确指定,从而无法支持枚举类型的前向声明。
经典做法
解决作用域不受限带来的命名冲突问题的一个简单方法是,给枚举变量命名时加前缀,如上面例子改成 COLOR_BLUE 以及 FEELING_BLUE。
一般说来,为了一致性我们会把所有常量统一加上前缀。但是这样定义枚举变量的代码就显得累赘。C 程序中可能不得不这样做。不过 C++ 程序员恐怕都不喜欢这种方法。替代方案是命名空间:
namespace Color
{
enum Type
{
RED=15,
YELLOW,
BLUE
};
};这样之后就可以用 Color::Type c = Color::RED; 来定义新的枚举变量了。如果 using namespace Color 后,前缀还可以省去,使得代码简化。不过,因为命名空间是可以随后被扩充内容的,所以它提供的作用域封闭性不高。在大项目中,还是有可能不同人给不同的东西起同样的枚举类型名。
更“有效”的办法是用一个类或结构体来限定其作用域,例如:定义新变量的方法和上面命名空间的相同。不过这样就不用担心类在别处被修改内容。这里用结构体而非类,是因为本身希望这些常量可以公开访问。
struct Color1
{
enum Type
{
RED=102,
YELLOW,
BLUE
};
};C++11 的枚举类
上面的做法解决了第一个问题,但对于后两个仍无能为力。庆幸的是,C++11 标准中引入了“枚举类”(enum class),可以较好地解决上述问题。
- 新的enum的作用域不在是全局的
- 不能隐式转换成其他类型
/**
* @brief C++11的枚举类
* 下面等价于enum class Color2:int
*/
enum class Color2
{
RED=2,
YELLOW,
BLUE
};
r2 c2 = Color2::RED;
cout << static_cast<int>(c2) << endl; //必须转!- 可以指定用特定的类型来存储enum
enum class Color3:char; // 前向声明
// 定义
enum class Color3:char
{
RED='r',
BLUE
};
char c3 = static_cast<char>(Color3::RED);具体实现见:
#include <iostream>
using namespace std;
/**
* @brief namespace解决作用域不受限
*/
namespace Color
{
enum Type
{
RED=15,
YELLOW,
BLUE
};
};
/**
* @brief 上述如果 using namespace Color 后,前缀还可以省去,使得代码简化。
* 不过,因为命名空间是可以随后被扩充内容的,所以它提供的作用域封闭性不高。
* 在大项目中,还是有可能不同人给不同的东西起同样的枚举类型名。
* 更“有效”的办法是用一个类或结构体来限定其作用域。
*
* 定义新变量的方法和上面命名空间的相同。
* 不过这样就不用担心类在别处被修改内容。
* 这里用结构体而非类,一是因为本身希望这些常量可以公开访问,
* 二是因为它只包含数据没有成员函数。
*/
struct Color1
{
enum Type
{
RED=102,
YELLOW,
BLUE
};
};
/**
* @brief C++11的枚举类
* 下面等价于enum class Color2:int
*/
enum class Color2
{
RED=2,
YELLOW,
BLUE
};
enum class Color3:char; // 前向声明
// 定义
enum class Color3:char
{
RED='r',
BLUE
};
int main()
{
// 定义新的枚举变量
Color::Type c = Color::RED;
cout<<c<<endl;
/**
* 上述的另一种方法:
* using namespace Color; // 定义新的枚举变量
* Type c = RED;
*/
Color1 c1;
cout<<c1.RED<<endl;
Color1::Type c11 = Color1::BLUE;
cout<<c11<<endl;
Color2 c2 = Color2::RED;
cout << static_cast<int>(c2) << endl;
char c3 = static_cast<char>(Color3::RED);
cout<<c3<<endl;
return 0;
}
类中的枚举类型
有时我们希望某些常量只在类中有效。 由于#define 定义的宏常量是全局的,不能达到目的,于是想到实用const 修饰数据成员来实现。而const 数据成员的确是存在的,但其含义却不是我们所期望的。
const 数据成员只在某个对象生存期内是常量,而对于整个类而言却是可变的,因为类可以创建多个对象,不同的对象其 const 数据成员的值可以不同。
不能在类声明中初始化 const 数据成员。以下用法是错误的,因为类的对象未被创建时,编译器不知道 SIZE 的值是什么。(c++11标准前)
class A
{
const int SIZE = 100; // 错误,企图在类声明中初始化 const 数据成员
int array[SIZE]; // 错误,未知的 SIZE
}; 正确应该在类的构造函数的初始化列表中进行:
class A
{
A(int size); // 构造函数
const int SIZE ;
};
A::A(int size) : SIZE(size) // 构造函数的定义
{
}
A a(100); // 对象 a 的 SIZE 值为 100
A b(200); // 对象 b 的 SIZE 值为 200 怎样才能建立在整个类中都恒定的常量呢?
别指望 const 数据成员了,应该用类中的枚举常量来实现。例如:
class Person{
public:
typedef enum {
BOY = 0,
GIRL
}SexType;
};
//访问的时候通过,Person::BOY或者Person::GIRL来进行访问。枚举常量不会占用对象的存储空间,它们在编译时被全部求值。
枚举常量的缺点是:它的隐含数据类型是整数,其最大值有限,且不能表示浮点。
decltype
基本使用
decltype的语法是:
decltype (expression)这里的括号是必不可少的,decltype的作用是“查询表达式的类型”,因此,上面语句的效果是,返回 expression 表达式的类型。注意,decltype 仅仅“查询”表达式的类型,并不会对表达式进行“求值”。
推导出表达式类型
int i = 4;
decltype(i) a; //推导结果为int。a的类型为int。与using/typedef合用,用于定义类型。
using size_t = decltype(sizeof(0));//sizeof(a)的返回值为size_t类型
using ptrdiff_t = decltype((int*)0 - (int*)0);
using nullptr_t = decltype(nullptr);
vector<int >vec;
typedef decltype(vec.begin()) vectype;
for (vectype i = vec.begin; i != vec.end(); i++)
{
//...
}这样和auto一样,也提高了代码的可读性。
重用匿名类型
在C++中,我们有时候会遇上一些匿名类型,如:
struct
{
int d ;
double b;
}anon_s;而借助decltype,我们可以重新使用这个匿名的结构体:
decltype(anon_s) as ;//定义了一个上面匿名的结构体泛型编程中结合auto,用于追踪函数的返回值类型
这也是decltype最大的用途了。
template <typename T>
auto multiply(T x, T y)->decltype(x*y)
{
return x*y;
}完整代码见:
#include <iostream>
#include <vector>
using namespace std;
/**
* 泛型编程中结合auto,用于追踪函数的返回值类型
*/
template <typename T>
auto multiply(T x, T y)->decltype(x*y)
{
return x*y;
}
int main()
{
int nums[] = {1,2,3,4};
vector<int> vec(nums,nums+4);
vector<int>::iterator it;
for(it=vec.begin();it!=vec.end();it++)
cout<<*it<<" ";
cout<<endl;
using nullptr_t = decltype(nullptr);
nullptr_t nu;
int * p =NULL;
if(p==nu)
cout<<"NULL"<<endl;
typedef decltype(vec.begin()) vectype;
for(vectype i=vec.begin();i!=vec.end();i++)
cout<<*i<<" ";
cout<<endl;
/**
* 匿名结构体
*/
struct
{
int d ;
double b;
}anon_s;
decltype(anon_s) as; // 定义了一个上面匿名的结构体
cout<<multiply(11,2)<<endl;
return 0;
}
判别规则
对于decltype(e)而言,其判别结果受以下条件的影响:
如果e是一个没有带括号的标记符表达式或者类成员访问表达式,那么的decltype(e)就是e所命名的实体的类型。此外,如果e是一个被重载的函数,则会导致编译错误。
否则 ,假设e的类型是T,如果e是一个将亡值,那么decltype(e)为T&&
否则,假设e的类型是T,如果e是一个左值,那么decltype(e)为T&。
否则,假设e的类型是T,则decltype(e)为T。
标记符指的是除去关键字、字面量等编译器需要使用的标记之外的程序员自己定义的标记,而单个标记符对应的表达式即为标记符表达式。例如:
int arr[4]则arr为一个标记符表达式,而arr[3]+0不是。
举例如下:
int i = 4;
int arr[5] = { 0 };
int *ptr = arr;
struct S{ double d; }s ;
void Overloaded(int);
void Overloaded(char);//重载的函数
int && RvalRef();
const bool Func(int);
//规则一:推导为其类型
decltype (arr) var1; //int 标记符表达式
decltype (ptr) var2;//int * 标记符表达式
decltype(s.d) var3;//doubel 成员访问表达式
//decltype(Overloaded) var4;//重载函数。编译错误。
//规则二:将亡值。推导为类型的右值引用。
decltype (RvalRef()) var5 = 1;
//规则三:左值,推导为类型的引用。
decltype ((i))var6 = i; //int&
decltype (true ? i : i) var7 = i; //int& 条件表达式返回左值。
decltype (++i) var8 = i; //int& ++i返回i的左值。
decltype(arr[5]) var9 = i;//int&. []操作返回左值
decltype(*ptr)var10 = i;//int& *操作返回左值
decltype("hello")var11 = "hello"; //const char(&)[9] 字符串字面常量为左值,且为const左值。
//规则四:以上都不是,则推导为本类型
decltype(1) var12;//const int
decltype(Func(1)) var13=true;//const bool
decltype(i++) var14 = i;//int i++返回右值学习参考:https://www.cnblogs.com/QG-whz/p/4952980.html
引用和指针
引用与指针
总论:
| 引用 | 指针 |
|---|---|
| 必须初始化 | 可以不初始化 |
| 不能为空 | 可以为空 |
| 不能更换目标 | 可以更换目标 |
引用必须初始化,而指针可以不初始化。
我们在定义一个引用的时候必须为其指定一个初始值,但是指针却不需要。
int &r; //不合法,没有初始化引用
int *p; //合法,但p为野指针,使用需要小心引用不能为空,而指针可以为空。
由于引用不能为空,所以我们在使用引用的时候不需要测试其合法性,而在使用指针的时候需要首先判断指针是否为空指针,否则可能会引起程序崩溃。
void test_p(int* p)
{
if(p != null_ptr) //对p所指对象赋值时需先判断p是否为空指针
*p = 3;
return;
}
void test_r(int& r)
{
r = 3; //由于引用不能为空,所以此处无需判断r的有效性就可以对r直接赋值
return;
}引用不能更换目标
指针可以随时改变指向,但是引用只能指向初始化时指向的对象,无法改变。
int a = 1;
int b = 2;
int &r = a; //初始化引用r指向变量a
int *p = &a; //初始化指针p指向变量a
p = &b; //指针p指向了变量b
r = b; //引用r依然指向a,但a的值变成了b引用
左值引用
常规引用,一般表示对象的身份。
右值引用
右值引用就是必须绑定到右值(一个临时对象、将要销毁的对象)的引用,一般表示对象的值。
右值引用可实现转移语义(Move Sementics)和精确传递(Perfect Forwarding),它的主要目的有两个方面:
- 消除两个对象交互时不必要的对象拷贝,节省运算存储资源,提高效率。
- 能够更简洁明确地定义泛型函数。
引用折叠
X& &、X& &&、X&& &可折叠成X&X&& &&可折叠成X&&
C++的引用在减少了程序员自由度的同时提升了内存操作的安全性和语义的优美性。比如引用强制要求必须初始化,可以让我们在使用引用的时候不用再去判断引用是否为空,让代码更加简洁优美,避免了指针满天飞的情形。除了这种场景之外引用还用于如下两个场景:
引用型参数
一般我们使用const reference参数作为只读形参,这种情况下既可以避免参数拷贝还可以获得与传值参数一样的调用方式。
void test(const vector<int> &data)
{
//...
}
int main()
{
vector<int> data{1,2,3,4,5,6,7,8};
test(data);
}引用型返回值
C++提供了重载运算符的功能,我们在重载某些操作符的时候,使用引用型返回值可以获得跟该操作符原来语法相同的调用方式,保持了操作符语义的一致性。一个例子就是operator []操作符,这个操作符一般需要返回一个引用对象,才能正确的被修改。
vector<int> v(10);
v[5] = 10; //[]操作符返回引用,然后vector对应元素才能被修改
//如果[]操作符不返回引用而是指针的话,赋值语句则需要这样写
*v[5] = 10; //这种书写方式,完全不符合我们对[]调用的认知,容易产生误解指针与引用的性能差距
指针与引用之间有没有性能差距呢?这种问题就需要进入汇编层面去看一下。我们先写一个test1函数,参数传递使用指针:
void test1(int* p)
{
*p = 3; //此处应该首先判断p是否为空,为了测试的需要,此处我们没加。
return;
}该代码段对应的汇编代码如下:
(gdb) disassemble
Dump of assembler code for function test1(int*):
0x0000000000400886 <+0>: push %rbp
0x0000000000400887 <+1>: mov %rsp,%rbp
0x000000000040088a <+4>: mov %rdi,-0x8(%rbp)
=> 0x000000000040088e <+8>: mov -0x8(%rbp),%rax
0x0000000000400892 <+12>: movl $0x3,(%rax)
0x0000000000400898 <+18>: nop
0x0000000000400899 <+19>: pop %rbp
0x000000000040089a <+20>: retq
End of assembler dump.
上述代码1、2行是参数调用保存现场操作;第3行是参数传递,函数调用第一个参数一般放在rdi寄存器,此行代码把rdi寄存器值(指针p的值)写入栈中;第4行是把栈中p的值写入rax寄存器;第5行是把立即数3写入到rax寄存器值所指向的内存中,此处要注意(%rax)两边的括号,这个括号并并不是可有可无的,(%rax)和%rax完全是两种意义,(%rax)代表rax寄存器中值所代表地址部分的内存,即相当于C代码中的*p,而%rax代表rax寄存器,相当于C代码中的p值,所以汇编这里使用了(%rax)而不是%rax。
我们再写出参数传递使用引用的C++代码段test2:
void test2(int& r)
{
r = 3; //赋值前无需判断reference是否为空
return;
}这段代码对应的汇编代码如下:
(gdb) disassemble
Dump of assembler code for function test2(int&):
0x000000000040089b <+0>: push %rbp
0x000000000040089c <+1>: mov %rsp,%rbp
0x000000000040089f <+4>: mov %rdi,-0x8(%rbp)
=> 0x00000000004008a3 <+8>: mov -0x8(%rbp),%rax
0x00000000004008a7 <+12>: movl $0x3,(%rax)
0x00000000004008ad <+18>: nop
0x00000000004008ae <+19>: pop %rbp
0x00000000004008af <+20>: retq
End of assembler dump.
我们发现test2对应的汇编代码和test1对应的汇编代码完全相同,这说明C编译器在编译程序的时候将指针和引用编译成了完全一样的机器码。所以C中的引用只是C对指针操作的一个“语法糖”,在底层实现时C编译器实现这两种操作的方法完全相同。
总结
C++中引入了引用操作,在对引用的使用加了更多限制条件的情况下,保证了引用使用的安全性和便捷性,还可以保持代码的优雅性。在适合的情况使用适合的操作,引用的使用可以一定程度避免“指针满天飞”的情况,对于提升程序稳定性也有一定的积极意义。最后,指针与引用底层实现都是一样的,不用担心两者的性能差距。
上述部分参考自:http://irootlee.com/juicer_pointer_reference/#
宏
宏中包含特殊符号
分为几种:#,##,\
字符串化操作符(#)
在一个宏中的参数前面使用一个#,预处理器会把这个参数转换为一个字符数组,换言之就是:#是“字符串化”的意思,出现在宏定义中的#是把跟在后面的参数转换成一个字符串。
注意:其只能用于有传入参数的宏定义中,且必须置于宏定义体中的参数名前。
例如:
#define exp(s) printf("test s is:%s\n",s)
#define exp1(s) printf("test s is:%s\n",#s)
#define exp2(s) #s
int main() {
exp("hello");
exp1(hello);
string str = exp2( bac );
cout<<str<<" "<<str.size()<<endl;
/**
* 忽略传入参数名前面和后面的空格。
*/
string str1 = exp2( asda bac );
/**
* 当传入参数名间存在空格时,编译器将会自动连接各个子字符串,
* 用每个子字符串之间以一个空格连接,忽略剩余空格。
*/
cout<<str1<<" "<<str1.size()<<endl;
return 0;
}上述代码给出了基本的使用与空格处理规则,空格处理规则如下:
- 忽略传入参数名前面和后面的空格。
string str = exp2( bac );
cout<<str<<" "<<str.size()<<endl;输出:
bac 3- 当传入参数名间存在空格时,编译器将会自动连接各个子字符串,用每个子字符串之间以一个空格连接,忽略剩余空格。
string str1 = exp2( asda bac );
cout<<str1<<" "<<str1.size()<<endl;输出:
asda bac 8符号连接操作符(##)
“##”是一种分隔连接方式,它的作用是先分隔,然后进行强制连接。将宏定义的多个形参转换成一个实际参数名。
注意事项:
(1)当用##连接形参时,##前后的空格可有可无。
(2)连接后的实际参数名,必须为实际存在的参数名或是编译器已知的宏定义。
(3)如果##后的参数本身也是一个宏的话,##会阻止这个宏的展开。
示例:
#define expA(s) printf("前缀加上后的字符串为:%s\n",gc_##s) //gc_s必须存在
// 注意事项2
#define expB(s) printf("前缀加上后的字符串为:%s\n",gc_ ## s) //gc_s必须存在
// 注意事项1
#define gc_hello1 "I am gc_hello1"
int main() {
// 注意事项1
const char * gc_hello = "I am gc_hello";
expA(hello);
expB(hello1);
}续行操作符(\)
当定义的宏不能用一行表达完整时,可以用”\”表示下一行继续此宏的定义。
注意 \ 前留空格。
#define MAX(a,b) ((a)>(b) ? (a) \
:(b))
int main() {
int max_val = MAX(3,6);
cout<<max_val<<endl;
}上述代码见:
#include <iostream>
#include <string>
#include <cstring>
#include <stdio.h>
using namespace std;
///===========================================
/**
* (#)字符串操作符
*/
///===========================================
#define exp(s) printf("test s is:%s\n",s)
#define exp1(s) printf("test s is:%s\n",#s)
#define exp2(s) #s
///===========================================
/**
*(##)符号连接操作符
*/
///===========================================
#define expA(s) printf("前缀加上后的字符串为:%s\n",gc_##s) //gc_s必须存在
#define expB(s) printf("前缀加上后的字符串为:%s\n",gc_ ## s) //gc_s必须存在
#define gc_hello1 "I am gc_hello1"
///===========================================
/**
* (\)续行操作符
*/
///===========================================
#define MAX(a,b) ((a)>(b) ? (a) \
:(b))
int main() {
///===========================================
/**
* (#)字符串操作符
*/
///===========================================
exp("hello");
exp1(hello);
string str = exp2( bac );
cout<<str<<" "<<str.size()<<endl;
/**
* 忽略传入参数名前面和后面的空格。
*/
string str1 = exp2( asda bac );
/**
* 当传入参数名间存在空格时,编译器将会自动连接各个子字符串,
* 用每个子字符串之间以一个空格连接,忽略剩余空格。
*/
cout<<str1<<" "<<str1.size()<<endl;
///===========================================
/**
* (#)字符串操作符
*/
///===========================================
const char * gc_hello = "I am gc_hello";
expA(hello);
expB(hello1);
char var1_p[20];
char var2_p[20];
// 连接后的实际参数名赋值
strcpy(var1_p, "aaaa");
strcpy(var2_p, "bbbb");
///===========================================
/**
* (\)续行操作符
*/
///===========================================
int max_val = MAX(3,6);
cout<<max_val<<endl;
return 0;
}
do{…}while(0)的使用
避免语义曲解
例如:
#define fun() f1();f2();
if(a>0)
fun()这个宏被展开后就是:
if(a>0)
f1();
f2();本意是a>0执行f1 f2,而实际是f2每次都会执行,所以就错误了。
为了解决这种问题,在写代码的时候,通常可以采用{}块。
如:
#define fun() {f1();f2();}
if(a>0)
fun();
// 宏展开
if(a>0)
{
f1();
f2();
};但是会发现上述宏展开后多了一个分号,实际语法不太对。(虽然编译运行没问题,正常没分号)。
避免使用goto控制流
在一些函数中,我们可能需要在return语句之前做一些清理工作,比如释放在函数开始处由malloc申请的内存空间,使用goto总是一种简单的方法:
int f() {
int *p = (int *)malloc(sizeof(int));
*p = 10;
cout<<*p<<endl;
#ifndef DEBUG
int error=1;
#endif
if(error)
goto END;
// dosomething
END:
cout<<"free"<<endl;
free(p);
return 0;
}但由于goto不符合软件工程的结构化,而且有可能使得代码难懂,所以很多人都不倡导使用,这个时候我们可以使用do{…}while(0)来做同样的事情:
int ff() {
int *p = (int *)malloc(sizeof(int));
*p = 10;
cout<<*p<<endl;
do{
#ifndef DEBUG
int error=1;
#endif
if(error)
break;
//dosomething
}while(0);
cout<<"free"<<endl;
free(p);
return 0;
}这里将函数主体部分使用do{…}while(0)包含起来,使用break来代替goto,后续的清理工作在while之后,现在既能达到同样的效果,而且代码的可读性、可维护性都要比上面的goto代码好的多了。
避免由宏引起的警告
内核中由于不同架构的限制,很多时候会用到空宏,。在编译的时候,这些空宏会给出warning,为了避免这样的warning,我们可以使用do{…}while(0)来定义空宏:
#define EMPTYMICRO do{}while(0)定义单一的函数块来完成复杂的操作
如果你有一个复杂的函数,变量很多,而且你不想要增加新的函数,可以使用do{…}while(0),将你的代码写在里面,里面可以定义变量而不用考虑变量名会同函数之前或者之后的重复。
这种情况应该是指一个变量多处使用(但每处的意义还不同),我们可以在每个do-while中缩小作用域,比如:
int fc()
{
int k1 = 10;
cout<<k1<<endl;
do{
int k1 = 100;
cout<<k1<<endl;
}while(0);
cout<<k1<<endl;
}上述代码见:
#include <iostream>
#include <malloc.h>
using namespace std;
#define f1() cout<<"f1()"<<endl;
#define f2() cout<<"f2()"<<endl;
#define fun() {f1();f2();}
#define fun1() \
do{ \
f1();\
f2();\
}while(0)
int f() {
int *p = (int *)malloc(sizeof(int));
*p = 10;
cout<<*p<<endl;
#ifndef DEBUG
int error=1;
#endif
if(error)
goto END;
// dosomething
END:
cout<<"free"<<endl;
free(p);
return 0;
}
int ff() {
int *p = (int *)malloc(sizeof(int));
*p = 10;
cout<<*p<<endl;
do{
#ifndef DEBUG
int error=1;
#endif
if(error)
break;
//dosomething
}while(0);
cout<<"free"<<endl;
free(p);
return 0;
}
int fc()
{
int k1 = 10;
cout<<k1<<endl;
do{
int k1 = 100;
cout<<k1<<endl;
}while(0);
cout<<k1<<endl;
}
int main() {
if(1>0)
fun();
if(2>0)
fun1();
f();
ff();
fc();
return 0;
}


